프로세스 vs 스레드
- 프로세스: 운영체제로부터 자원을 할당받는 작업의 단위
- 스레드: 프로세스에 할당된 자원을 사용하는 실행 흐름의 단위(하나의 프로세스 안에서 발생)

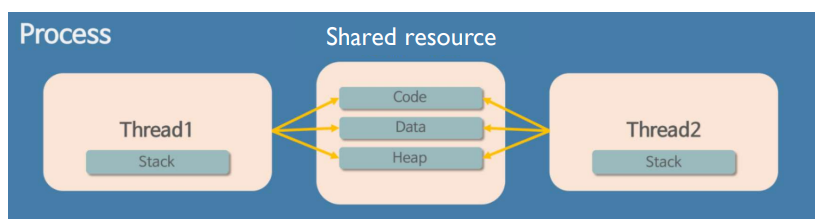
Memory Space
- 프로세스: 프로세스마다 독립된 메모리 공간을 가짐
- 스레드: 부모 프로세스의 메모리 공간을 공유함
Creation Overhead
- 프로세스: 각 프로세스마다 고유한 메모리 공간과 자원을 할당하기 때문에 비용이 상대적으로 높음
- 스레드: 프로세스의 자원을 공유해서 사용하기 때문에 비용이 상대적으로 낮음
Resource Sharing
- 프로세스: 프로세스 간 IPC 없이 자원 공유 불가능
- 스레드: 메모리, 파일 디스크립터 등 프로세스의 자원을 다 같이 공유하여 사용
스레드

- 프로세스 안에서 생성됨
프로세스의 메모리 할당 구조

- Code 영역: 프로그램 실행 코드를 위한 공간. 프로그래머가 작성한 코드가 저장됨.
- Data 영역: 전역 변수를 위한 공간. 코드가 실행될 때 사용되는 변수를 저장함.
- Stack 영역: 지역 변수처럼 일시적인 데이터를 저장하는 공간. 함수가 호출될 때 stack영역이 할당되었다가 함수가 끝나고 return되면 destroy됨.
- Heap 영역: 동적으로 할당되는 데이터를 위한 공간.
Context switching
- 프로세스/스레드가 CPU/core에서 실행되다가 다른 프로세스/스레드로 바뀌는 것
- context: 프로세스/스레드의 state(=CPU, memory의 state)
Context Switching이 필요한 이유
- Multiple process, thread가 동시에 동작하는 것처럼 보이게 하기 위해서
- Multiple process, thread가 CPU time을 공정하게 나눠 사용할 수 있도록 하기 위해서
- 우선순위가 높은 task부터 빨리빨리 처리하기 위해서
Context Switching이 발생하는 경우
- time slice를 다 쓴 경우, 프로세스/스레드가 주어진 시간 할당량을 다 사용했을 때
- I/O 작업을 수행할 때(I/O 작업은 많은 시간이 소요됨)
- 다른 자원을 기다려야 할 때
- 하드웨어나 소프트웨어 인터럽트가 발생했을 때
Context Switching은 누가 수행하나?
- OS 커널에 의해 수행됨
- 커널은 운영 체제 안에서 핵심 기능을 수행하는 엔티티임
Process Context Switching vs. Thread Context Switching
공통점(In Common)
- 커널 모드에서 실행
- 프로세스가 하드웨어 관련 작업이나 컴퓨터의 다양한 자원을 처리해야할 때, 프로세스가 직접적으로 자원에 접근하지 않고 운영 체제를 통해 접근하는 모드이다. 이 때, 제어는 프로세스에서 커널로 전송되어 커널에 의해 실행된다.
- CPU 레지스터의 상태를 변경e.g., PC, 스택 포인터 등
- 레지스터: CPU가 다양한 명령을 수행하기 위해 필요한 데이터를 저장하는 공간
차이점
- 가상 메모리 관련 추가 처리
- Process context switching의 경우, 가상 메모리 주소와 관련된 추가적인 처리를 진행해야 함. → 각 프로세스가 독립된 메모리 공간을 가지고 있으므로, 가상 주소 공간을 적절히 매핑해야 함.
- Thread context switching의 경우, 각 스레드는 프로세스 내에서 동일한 가상 메모리 공간을 공유하므로 추가적인 메모리 매핑 작업이 필요하지 않음.
- 공유 메모리 영역
- Process context switching의 경우, 각 프로세스는 메모리 영역이 완전히 분리되어 있기 때문에 메모리 공유가 없음
- Thread context switching의 경우, 프로세스의 주소 공간의 code, data, heap 영역을 공유함.
스레드의 자원 공유
- 프로세스의 메모리 영역(Code, Data, Heap, and Stack) 중에서 Stack은 복사되어 스레드마다 별도로 할당되고 나머지 Code, Data, Heap 영역은 프로세스 내에서 다른 스레드와 공유함.
- 각 스레드는 분리된 Stack 영역을 가짐. → 각 스레드가 서로 다른 실행 흐름을 갖기 때문에. → Stack 영역에는 함수 호출 시 함수의 지역 변수, 함수의 복귀 주소, 호출에 필요한 기타 정보 등이 저장된다. 함수가 호출되면 해당 함수의 지역 변수와 함께 함수 호출 스택 프레임이 생성되고, 함수가 return 되면 스택에서 해당 프레임이 제거된다. —> 각 스레드는 독립적으로 함수 호출, return을 수행하며, 각각의 실행 흐름을 제어한다.
- 하지만, Heap 영역은 하나임. → 서로 다른 스레드가 Heap 영역에 read, write 할 수 있음
pthread_create()
새로운 스레드를 생성하는 함수
#include <pthread.h>
int pthread_create(pthread_t *thread, pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);- thread: 스레드가 사용할 ID
- attr: 스레드의 attribute, 보통 NULL로 세팅해서 사용
- start_routine: 스레드에서 사용할 function을 가리키는 포인터, 스레드로 수행할 일, 스레드의 메인 함수
- arg: 스레드의 메인 함수에서 사용할 파라미터
- return 값
- EAGAIN:
- EINVAL
- EPERM


pthread_join()
스레드의 종료를 기다리는 함수
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);- thread: 스레드의 id
- retval: 스레드의 메인 함수의 return 값이 저장될 포인터 변수의 주소 값
- return 값
- 성공: 0
- 실패: EDEADLK, ESRCH




Critical Section
- 어떠한 메모리 공간에 동시에 접근하는 경우, Critical Section일 가능성이 존재
- 스레드1과 스레드2가 번갈아 num 변수에 1씩 더해서 num 변수를 증가시키는 연산을 해보자.

- 먼저 스레드1이 num에 접근하여 99에 1을 더한 100을 저장하려고 한다.

- 스레드1이 num에 저장된 값을 참조하고 1을 증가시키는 작업을 완료했다. 이제 num에 100을 저장해야 하지만, 이 작업이 이루어지기 전에 실행 순서가 스레드2로 넘어가는 상황(4번)을 고려해보자.

- 다행히, 스레드2는 증가 연산을 완전히 완료하고 증가된 값을 num에 저장한다.
스레드1에 의해 num에 저장된 값이 100으로 증가하지 않았었기 때문에, 스레드2에 의해 참조된 num에 저장된 값은 여전히 99였다. 결국 num의 값은 스레드2에 의해 100으로 저장된다.

- 스레드2의 실행이 끝나고 다시 스레드1의 실행 순서가 되었을 때는, 이미 스레드2가 num의 값을 100으로 저장한 상태이다. 때문에, 스레드1이 이전에 증가 연산을 수행했던 100이라는 값을 num에 저장해도, num입장에서는 스레드2가 저장했던 100이 다시 저장되는 격이다. 스레드1과 스레드2가 각각 1씩 증가시켰음에도 불구하고, 완전히 잘못된 값이 저장될 수 있는 것이다.

→ 이러한 문제를 방지하기 위해서는 한 스레드가 변수 num에 접근하여 작업을 완료할 때까지, 다른 스레드가 해당 변수에 접근하지 못하도록 해야 한다. 이것이 동기화(Synchronizatoin)이다. 동기화를 통해 한 번에 하나의 스레드만이 공유 자원에 접근하여 작업을 수행할 수 있도록 해야 한다.
Critical Section은 어디에 있는가?
함수 내에서 두 개 이상의 스레드가 동시에 실행되는 경우, 문제를 일으킬 수 있는 코드가 한 줄 이상 포함된 코드 블록을 의미
- 전역 변수 자체는 critical section이 아님. 얘는 단순히 메모리 할당이 필요한 변수 선언에 불과
- 전역 변수에 접근하는 두 문장이 critical section임. 변수를 직접적으로 변경하거나 참조하는 코드 부분이 동시에 여러 스레드에 의해 실행되는 경우 문제가 발생할 수 있음
- 전역 변수에 접근하는 두 문장이 critical section임. 변수를 직접적으로 변경하거나 참조하는 코드 부분이 동시에 여러 스레드에 의해 실행되는 경우 문제가 발생할 수 있음

Synchronization
- 스레드의 접근 순서 때문에 발생하는 문제를 해결하기 위한 방법
- 동기화가 필요한 상황
- 같은 메모리 영역에 동시에 접근하는 경우
- 같은 메모리 영역에 접근하는 스레드의 실행 순서가 정해져 있는 경우
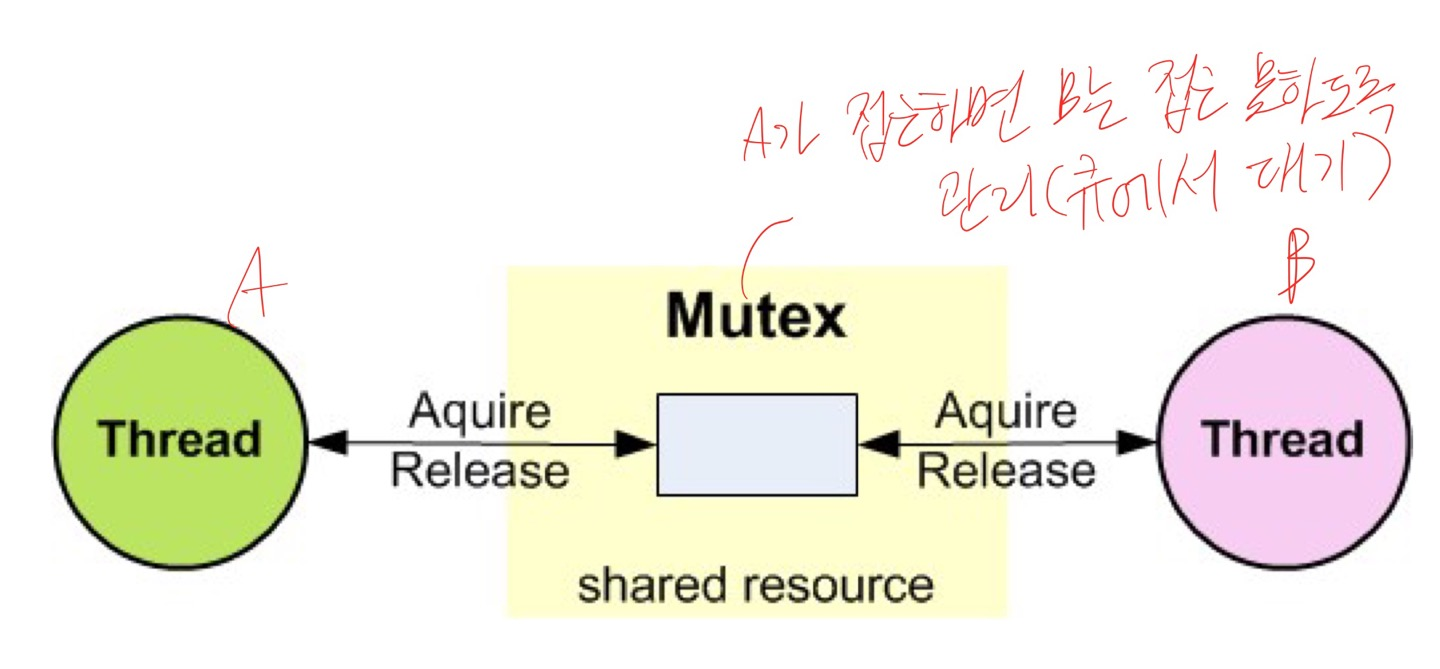
Mutex
Mutual Exclusion
- 스레드의 동시 접근을 허용하지 않는 것
- 스레드의 동기화 기법 중 하나
- lock 시스템과 동일함
- 시간 동기화가 필요할 때 사용
- 한 스레드가 work면 다른 스레드를 stop함
pthread_mutex_init()
mutex 초기화
#include <pthread.h>
int pthread_mutex_init([pthread_mutex_t *mutex, const pthread_muteexattr_t *attr);
- mutex: mutex의 참조 값을 저장할 공간의 주소
- attr: 초기화 시킬 때 정의할 mutex의 특징, 기본 operation을 사용하고 싶다면 NULL 넣기
- return 값
- 성공: 0
- 실패: EINVAL, EBUSY, EINVAL
pthread_mutex_lock & pthread_mutex_unlock
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
- mutex: lock할 mutex 객체
- return 값
- 성공: 0
- 실패: 에러코드
- critical section에 들어가기 전에 pthread_mutex_lock()을 호출
- 이 함수를 호출했을 때 다른 스레드가 이미 critical section을 수행하고 있다면, pthread_mutex_lock()은 return 되지 않음 → 다른 스레드가 pthread_mutex_unlock()으로 critical section을 빠져 나올 때까지 blocking state로 존재
pthread_mutex_destroy()
자원 반납
#include <pthread.h>
int pthread_mutex_destriy(pthread_mutex_t *mutex);
- mutex: destroy할 mutex 객체
- return 값
- 성공: 0
- 실패: 에러 코드
Semaphore
여러 스레드가 공통 자원에 접근하는 것을 제어하고 concurrent 시스템에서 critical section 문제를 피하기 위해 사용되는 변수/추상 데이터 타입
- CPU가 변수를 보고 critical section에 접근할지 말지를 결정 → 변수를 통해 관리

sem_init/sem_destory
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned vlaue);
int sem_destroy(sem_t *sem);
- sem:
- sem_init: 초기화할 세마포어 객체
- sem_destory: 자원 반납할 세마포어 객체
- pthread
- 0: 하나의 프로세스 안에서만 접근 가능한 세마포어로 초기화
- 0이 아닌 값: 두 개 이상의 프로세스에서 접근 가능한 세마포어로 초기화
- value: 세마포어의 초기값
- return 값
- 성공: 0
- 실패: 0이 아닌 값
sem_post/sem_wait
#include <semaphore.h>
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem);
- sem: +1 또는 -1 세마포어 객체
- return 값
- 성공: 0
- 실패: 0이 아닌 값
- sem_init() 호출하여 OS가 세마포어 객체를 생성하고 Semaphore Value를 초기값으로 세팅
- sem_post() 호출하면 Semaphore Value가 +1, sem_wait() 호출하면 Semaphore Value가 -1
- Semaphore Value는 0보다 작아질 수 없기 때문에 Semaphore Value가 0일 때 sem_wait()이 호출되면 해당 스레드는 Semaphore Value가 0보다 큰 값을 갖게 될 때까지 blocking state가 됨
→ Semaphore Value가 0 또는 1의 값을 가짐. 이걸 binary semaphore라고 함.

스레드의 terminate
- 스레드의 main function이 return 되어도 스레드가 자동으로 destroy 되진 않음
- 프로그래머가 pthread_join()이나 pthread_detach()로 스레드를 죽여야 됨. → 그렇지 않으면 스레드에 의해 할당된 메모리 공간이 남아있게 됨
- pthread_join()
- (-): 함수가 return 될 때까지 blocking state를 유지함
- pthread_detach()
- 스레드에 할당된 메모리를 deallocated
'CS > Network' 카테고리의 다른 글
| 11_Security (5) | 2024.07.24 |
|---|---|
| 06_Multiplexing (1) | 2024.07.24 |
| 04_Multiprocess (2) | 2024.07.24 |
| 03_TCP Connections (0) | 2024.07.24 |
| 02_Socket_IO (2) | 2024.07.23 |